An intelligent approach to mobile news

SEARCH AND SUMMARIZE: Taylor Berg-Kirkpatrick (left) and Mohit Bansal, EECS Ph.D. students, developed a computer model that makes it easy to read summaries of news articles on smartphones and cell phones. (Photo by Rachel Shafer.)
Do you read news on your cell phone? According to a 2010 Pew Research Center study, 33 percent of cell phone owners now check news, weather and sports headlines on their mobile phones.
Yet searching for and reading news on a 3.5-inch screen isn’t easy. News aggregator apps and search engines like Google and Yahoo improve the experience, but “you have to scroll around and back out a lot,” says EECS Ph.D. student Taylor Berg-Kirkpatrick, 26, who owns an iPhone. “We know from experience, trying to read news on mobile phones sucks.”
Earlier this year, Berg-Kirkpatrick teamed up with fellow EECS Ph.D. student Mohit Bansal, 25, on a project that may alleviate the problem. Called “Automatic Summarization of Mobile Search,” it’s a tool that scans hundreds of documents online and automatically compiles a short summary derived from the text. Think of it as Zagat’s for news but without quotations. The summary, with its clean, simple design, fits snugly into a mobile phone screen. Users can lengthen or shorten the summary, scroll through multiple news items to catch the top news or view summaries based on a search query.
In May, Qualcomm selected Bansal and Berg-Kirkpatrick as one of eight teams to receive its highly competitive Qualcomm Innovation Fellowship, which comes with a one-year, $100,000 grant. “We liked their project because it was closely coupled with their Ph.D. research, but they had a great understanding of the potential applications and how users could benefit 5 to 10 years down the road,” says John Smee, director of engineering for Qualcomm’s corporate R&D group and one of the competition’s judges.
Test out the summarizer on your mobile phone for the latest news. You can also summarize search results by clicking on “Search.”
Example: enter the term “Libya” and get a summary of current news articles that match this query.
Bansal and Berg-Kirkpatrick specialize in artificial intelligence (A.I.), working in EECS associate professor Dan Klein’s natural language processing and machine learning group. Their project applies A.I. methodologies to what is essentially the job of a human editor or researcher. While it’s impossible for a person to read and summarize 500 documents in a few seconds, a computer can do it handily. The difficult part: how do you teach a computer to read and write? Or, in this case, rewrite?
Berg-Kirkpatrick began by building a summarization model that uses the cutting-plane algorithm, a method of mathematically optimizing objective functions that dates back to the 1950s. To build a democratic summary, one that covers the most common ideas found in the articles, Berg-Kirkpatrick’s model scans the documents looking for intersections—repeated sentences, phrases or series of words—and pulls the common points. For example, say one of the main points identified is “Lindsay Lohan jailed.”
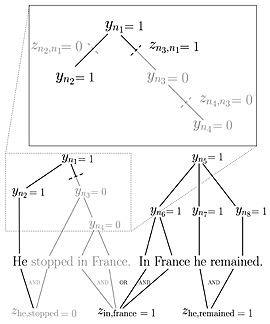
STRUCTURED LEARNING: This figure details how the summarizer builds a summary of the document collection by eliminating unnecessary sentences, phrases and words. Those cuts are balanced against the values of the concepts covered by the resulting summary. Both costs and values are learned automatically from human-written summaries in a structured learning algorithm. (Courtesy the researchers.)
The next step is to add mathematical “features,” qualities such as how often an idea appeared across the document collection. A programmer designs these features in order to indicate to the system which aspects of a summary may be important. In our example, an important feature of the phrase “Lindsay Lohan jailed” is that it occurs in many of the news articles within the document set.
Special features can even be derived by measuring the frequency and context of words and phrases on the Internet. The model scans the web and finds that “Lindsay Lohan jailed” occurs somewhat on the web, yet occurs a lot within the document collection, and therefore might be especially important for the summary. “Lindsay Lohan jailed,” the model decides, should go in the summary. On the other hand, the concept “It was reported” occurs everywhere on the web, and hence the model recognizes it’s a throwaway phrase and not important for the summary. These web-based features, based on Bansal’s Ph.D. work, will better estimate which concepts should be included in the summary.
Now comes the machine learning part. So far, the features might produce a good summary or an error-laden one. It’s up to the learning algorithm to decide how to value the features. The two students use machine learning to train their model by giving it sample article sets and human-written summaries. Based on these examples, the model learns how to optimally set the feature values. When presented with a new article set, the model makes generalizations from the samples and compiles a new summary. “Now you have a system that can do it forever,” says Berg-Kirkpatrick.
The EECS researchers say they will spend the next year optimizing the summarizer to accommodate a wide range of news topics and scaling up the model to accommodate thousands, even hundreds of thousands of documents. In the future, they hope their project will be adopted by industry, but they themselves would like to remain in academic research.
For these Berkeley computer scientists, the challenges posed by natural language processing and machine learning are irresistible. Their project is a case in point. Reading comprehension and summary writing, tasks surmounted by fourth-graders, remain steep challenges for computers. Getting computers to master language is important, explains Berg-Kirkpatrick, because it will ultimately make machines behave like us. “Language is the most profound thing, really,” he says. “It’s what makes us human.”
